Осень 2009 года принесла некоторое оживление на рынок графических адаптеров. В сентябре компания AMD презентовала видеокарты ATI Radeon HD 5870 и ATI Radeon HD 5850 на основе процессоров RV870. Сразу же стало понятно, что до появления нового флагмана компании NVIDIA именно эти видеокарты являются самими производительными из всех однопроцессорных графических адаптеров. По сравнению со своими предшественниками - ATI Radeon HD 4870 (которые сами являются весьма удачными продуктами компании AMD) – видеокарты ATI Radeon HD 5870 обладают вдвое более высокой производительностью. Причина столь впечатляющего результата кроется в двукратном увеличении числа основных вычислительных блоков графического процессора: потоковых процессоров, текстурных модулей, блоков растеризации и пр. Модернизация видеочипов именно в этом направлении привела к вполне ожидаемому резкому увеличению и количества транзисторов, из которых состоят интегральные схемы – если конструкция процессора ATI Radeon HD 4870 предусматривала использование 0,956 млрд транзисторов, то в случае ATI Radeon HD 5870 их количество составило уже 2,15 млрд. Но даже эта астрономическая цифра меркнет перед новым продуктом NVIDIA, анонсированного представителями компании в ходе конференции GPU Technologies Conference – графическим процессором NVIDIA Fermi.
Разработчики из Калифорнии основательно подошли к созданию графического процессора нового поколения – микрочипы Fermi (кстати, их «старое» кодовое обозначение – GT300) состоят из более чем трех миллиардов транзисторов. Эта цифра сразу на 40% выше количества транзисторов у процессора RV870, при том, что они являются продуктами одного поколения и изготавливаются по одному технологическому процессу – 40-нм на мощностях тайваньской компании TSMC. Если сравнивать процессоры Fermi с решениями предыдущего поколения GT200, то преимущество в количестве транзисторов и вовсе двукратное – 1,4 млрд против 3 млрд. Увеличение количества транзисторов вполне предсказуемо сказалось на характеристиках процессоров: по сравнению с GT200 увеличено до 512 количество вычислительных блоков, увеличена до 384 бит разрядность интерфейса графической памяти (шесть 64-разрядных блоков), реализована поддержка памяти стандарта GDDR5 максимальным объемом аж до 6 Гб. Надеемся, что все читатели помнят о поддержке процессорами GT200 стандарта GDDR3, а значит, переход на более скоростную графическую память позволит заметно увеличить возможности соответствующей подсистемы видеокарт. Ожидалась и аппаратная поддержка DirectX 11, которая была реализована разработчиками. Но на этом сюрпризы не заканчиваются, ведь дополнительные транзисторы «потрачены» не только на простое увеличение количества исполнительных блоков, как сделали инженеры AMD/ATI. В отличие от их продукта, графический процессор имеет заметно переработанную архитектуру, в которой реализовано значительное количество интересных и передовых (для графических процессоров как класса) нововведений.

На «верхнем» уровне архитектуры графических процессоров существенных качественных отличий не наблюдается. С этой позиции Fermi можно рассматривать всего лишь как масштабированную версию графических процессоров GT200. Но как только мы обращаем свое внимание на «нижние» уровни архитектуры, на ее фундамент, то сразу же появляются существенные нововведения инженеров NVIDIA. Первое на что необходимо обращать внимание – на графические ядра, которые ранее обозначались как потоковые процессоры (SP - Streaming Processor). Сейчас разработчики вместо привычного термина перешли на использования термина CUDA-ядер (CUDA Core). В случае графических интегральных микросхем G80 и GT200 разработчики объединяли по восемь потоковых процессоров в единые группы – потоковые мультипроцессорные SM-блоки (SM - Streaming Multiprocessor). Похожая организация сохранена и для процессоров Fermi, за тем лишь исключением, что теперь в единый блок объединяются не восемь, а тридцать два ядра. В зависимости от конкретной реализации, в основу графических процессоров NVIDIA Fermi будут входить до шестнадцати SM-блоков, состоящих из 32 CUDA-ядер, оптимизированных для работы с вычислениями общего назначения. В результате и получаются 512 вычислительных ядра, которые и являются базой для высочайшей производительности процессоров.
В дополнение к упомянутым CUDA-ядрам, в состав мультипотоковых блоков входят и дополнительные вычислительные элементы. Речь идет о блоках Special Function Unit (SFU), основная область применения которых - трансцендентальная математика и интерполяция. Впрочем, блоки SFU сложно назвать главными исполнительными элементами графического процессора. На это указывает и тот факт, что разработчики решили лишь удвоить количество этих компонентов для каждого из SM-блоков графического процессора – до четырех штук.
К сожалению, более подробную информацию об основных исполнительных компонентах архитектуры NVIDIA Fermi разработчики пока предпочли не разглашать. В данном случае за кадром остались такие элементы, как блоки растеризации, текстурной фильтрации, и многое другое, что непосредственно касается возможностей процессоров по обработке трехмерной графики. Поэтому пока практически невозможно сказать, насколько интереснее архитектура Fermi применительно к компьютерным играм по сравнению со своими предшественниками в лице GT200.
Помимо исполнительных блоков, отвечающих непосредственно за обработку информации, каждый из SM-блоков графического процессора на основе архитектуры NVIDIA Fermi оснащается еще и блоками временного хранения данных – кэш-память. В случае видеочипов предыдущих поколений разработчики также оснащали SM-блоки кэш-памятью первого и второго уровней фиксированным объемом 24 Кб и 256 Кб соответственно. Но использовалась она лишь для хранения «текстурных» данных, к тому же, блок кэш-памяти уровня L1 распределялся между тремя потоковыми мультипроцессорными блоками. Графические процессоры следующего поколения оснащены уже универсальной кэш-памятью, причем каждому SM-блоку соответствует собственный блок кэш-памяти первого уровня. Но что самое важное, эта память является конфигурируемой. Что это означает? Каждый SM-блок имеет доступ к 64 Кб памяти, которая может быть разделена непосредственно на кэш-память первого уровня и разделяемую память, причем разделена двумя способами: 48 Кб/16 Кб, либо 16 Кб/48 Кб. Такой подход позволяет решить сразу несколько задач. Во-первых, возможность различной конфигурации кэш и разделяемой памяти означает полную совместимость с приложениями, оптимизированными для работы с графическими процессорами GT200 с их памятью объемом 16 Кб. Во-вторых, при выполнении вычислений общего назначения, специализированная традиционная «текстурная» кэш-память оказывается неэффективной – эта проблема решена в случае Fermi с ее универсальной кэш-памятью первого и второго уровней. В-третьих, возможность различной конфигурации кэш-памяти позволяет с максимальной эффективностью организовать работу программного обеспечения, оптимизированного для работы с большим объемом кэш-памяти – до 48 Кб. И последнее нововведение – увеличение объема универсальной кэш-памяти второго уровня до 768 Кб, которое позволяет существенно повысить производительность при работе с так называемыми атомарными операциями, часто используемыми при вычислениях общего назначения. Согласно заверениям разработчиков, эффективность работы повышается по сравнению с GT200 в 4 – 20 раз (!).
После краткого обзора аппаратной составляющей архитектуры графических процессоров NVIDIA Fermi стоит перейти к разговору о механизме работы столь сложных интегральных микросхем, состоящих из трех миллиардов транзисторов. Несколько лет назад главной тенденцией развития процессоров (не только графических, но и центральных процессоров) было увеличение их рабочей частоты и специализация на однопоточных вычислениях. Теперь акценты сместились в сторону многопоточных вычислений, что наложило свой отпечаток на конструкцию самих интегральных микросхем – начался период увеличения процессорных ядер на едином кристалле. Справедливости ради стоит отметить, что этот процесс в случае графических процессоров начался значительно раньше, нежели в индустрии центральных процессоров. Объясняется это особенностью представления данных, которые приходится обрабатывать видеочипу – вычисления легко параллелятся, чем и воспользовались разработчики. Постепенная эволюция графических процессоров привела к тому, что микросхемы G80 могли обрабатывать до 12288 потоков одновременно. С приходом монструозных процессоров GT200 количество обрабатываемых в параллельном режиме потоков команд и данных увеличено до рекордных 30720 единиц. Казалось бы, развитие видеочипов и дальше пойдет по выбранному ранее пути, однако анонс NVIDIA Fermi показал, что это не так. Графические процессоры нового поколения могут обрабатывать 24576 потоков одновременно. Но это отнюдь не означает, что новинки в чем-то уступают своим предшественникам. Отнюдь. Как оказалось, и как нам сообщают сотрудники компании NVIDIA, рекордные возможности интегральных схем по многопоточной обработке данных еще не означают эффективную работу всех элементов процессора. Оказывается, значительную роль в общей производительности видеочипа играет не многопоточность, а эффективное распределение задач между отдельными блоками процессора и разделяемая память. В случае NVIDIA Fermi существенную роль играет наличие двух Warp-планировщиков, которые с большей эффективностью распределяют команды и данные для исполнения.
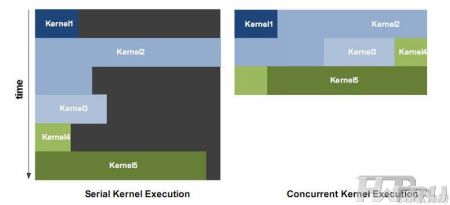
Продолжаем далее изучать методы повышения эффективности работы графического процессора NVIDIA Fermi. Теперь предлагаем обратить свое внимание на возможности параллельного выполнения видеочипов программных ядер (kernel). В среде программирования графических процессоров программным ядром называется не что иное, как функции и небольшие программы. Процессоры GT200 были способны работать с ядрами только в последовательном режиме – пока не выполнено ядро с первым номером остальные дожидаются своей очереди. Даже в том случае, если аппаратные возможности процессора позволяют загружать и выполнять следующую функцию/программу (kernel) параллельно с обработкой предыдущей. В том случае, если идет работа только с графическими приложения никаких проблем не возникает. Трудности появляются в случае работы с вычислениями общего назначения – не все функции и программы полностью загружают аппаратные ресурсы графического процессора, в результате, эффективность использования видеочипов падает. Разумеется, в случае архитектуры NVIDIA Fermi такая проблема решена – многочисленные kernel могут обрабатываться в параллельном режиме, полностью загружая работой ресурсы графического процессора. Необходимость в такой модернизации архитектуры более чем обоснована. Во-первых, по задумке разработчиков графические процессоры NVIDIA Fermi должны были найти свое применение не только в компьютерной графике, но и в не меньшей мере работать с вычислениями общего назначения. Во-вторых, размеры SM-блоков в случае NVIDIA Fermi значительно увеличены, по сравнению с видеочипами предыдущего поколения, а значит, их простой обходится куда дороже, и было необходимо оптимизировать этот аспект их работы. По заявлениям разработчиков, такие изменения в архитектуре позволяют на порядок повысить производительность Fermi-процессоров, особенно это будет заметно при просчете физики силами самого видеочипа – мы уже почти забыли о технологии PhysX. Теперь она возвращается, но уже в качестве функции самого графического процессора, а не отдельного сопроцессора. 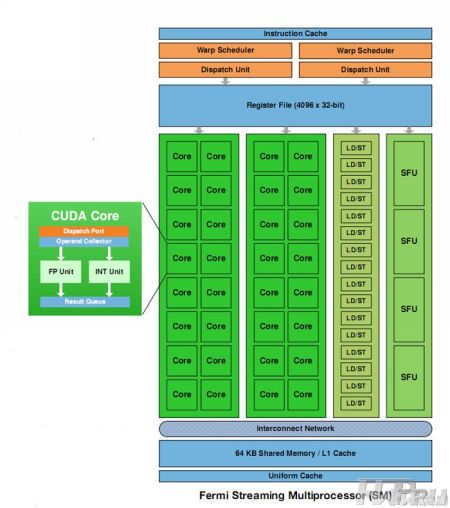
Важнейшей особенностью NVIDIA Fermi, которая, впрочем, не столь интересна любителям компьютерных игр, является поддержка кода коррекции ошибок. Такая функциональность появляется в индустрии графических процессоров впервые – все на что были способны современные видеочипы, например, AMD Radeon HD 5870, это регистрация ошибок, но не их коррекция. Но если эта функциональность оказывается практически бесполезной для геймеров, на кого рассчитана поддержка ECC? В первую очередь, разработчики компании NVIDIA преследовали цель привлечь внимание к своему продукту со стороны сборщиков высокопроизводительных вычислительных систем, вплоть до суперкомпьютеров. Дело в том, что в этой сфере поддержка кода коррекции ошибок является обязательной. Только по этой причине компании NVIDIA не удалось сделать популярным системы Tesla – они не обладали поддержкой ECC.
И последнее, что хотелось бы отметить в кратком обзоре архитектуры NVIDIA Fermi – унифицированную 64-разрядную схему адресации памяти. Необходимость унификации памяти объясняется желанием реализовать поддержку языка C++, тогда как 64-разрядная адресация памяти позволяет графическому процессору работать со значительно бoльшим объемом памяти. На данный момент сообщается, что архитектура NVIDIA Fermi позволяет процессору работать с адресным пространством объемом до 1 Тб. Впрочем, уникальные особенности видеочипов нового поколения можно рассматривать лишь в качестве демонстрации уникальных возможностей архитектуры – видеокарты для потребителей в течение ближайших нескольких лет вряд ли смогут полностью раскрыть заложенный в графические процессоры потенциал - вряд ли в ближайшее время на рынке появятся адаптеры, оснащенные памятью объемом свыше 4 Гб.
Рассмотрев основные особенности новейшей архитектуры NVIDIA Fermi, можно сказать следующее. Инженеры при работе над ней существенное внимание уделили расширению производительности и функциональности графических процессоров при работе с вычислениями общего назначения. Более того, информация о компонентах архитектуры, которые могли бы сказать о ее производительности при работе с чисто графическими приложениями, была официальными источниками опущена. Другими словами, разработчики поставили перед собой цель создания не просто игрового решения, но намного более универсального продукта. Первые шаги в том же направлении уже делала компания IBM, когда разрабатывала центральный процессор Cell, нашедший свое применение в целом спектре вычислительных систем, от игровых консолей Sony PS3, до мощных суперкомпьютеров. По всей видимости, такая судьба ожидает и графические процессоры на основе архитектуры NVIDIA Fermi. По крайней мере, некоторые производители мощных вычислительных систем уже объявили о своем интересе к новейшей архитектуре. При этом потенциал архитектуры столь высок, что разработчики суперкомпьютеров спешат заявить о возможности создания систем, производительность которых в разы превышает производительность лучших современных суперкомпьютеров. Впрочем, и во время работы в условиях современного персонального компьютера графические процессоры NVIDIA Fermi смогут раскрыть свой незаурядный потенциал – компания обещает, что их новое детище окажется куда мощнее свого конкурента AMD Radeon HD 5870, в том числе и при работе исключительно с трехмерной графикой. А уж если задействовать и возможности процессора для вычислений общего назначения (например, для обработки игровой физики), то равных ему сегодня попросту не будет.
 Сама NVIDIA рассматривает Fermi, а также платформу для портативной электроники Tegra в качестве основополагающих элементов для успешного ведения бизнеса в следующем году. По этой причине в NVIDIA пока отказываются раскрывать дополнительную информацию об архитектуре Fermi, в частности, ничего не известно о производительности графических процессоров при обработке трехмерной графики. Сообщается, что грядущие новинки будут производительнее своих конкурентов, но сколь значительным окажется отрыв NVIDIA Fermi, пока не ясно – можно только строить предположения. Впрочем, это абсолютно не отменяет того факта, что архитектура NVIDIA Fermi обладает целым спектром уникальных особенностей, которые уже сегодня привлекают к ней внимание не только пользователей ПК, но и научного сообщества.
Вместо резюме ко всему вышесказанному предлагаем читателям еще раз ознакомиться с основными преимуществами архитектуры NVIDIA Fermi по сравнению со своими предшественниками, и вспомнить, за счет чего новейшие графические процессоры будут завоевывать сердца геймеров и, в не меньшей степени, профессиональных пользователей, работающих с серьезным и чрезвычайно требовательным к аппаратным ресурсам программным обеспечением.

Главные особенности архитектуры NVIDIA Fermi:
увеличение количества CUDA-блоков до 32 штук на каждый потоковый процессор;
восьмикратное увеличение пиковой производительности при вычислениях с плавающей запятой двойной точности (по сравнению с GT200);
двойной блок планировки Dual Warp Scheduler одновременно планирует и отправляет на обработку инструкций из двух пулов (warp) одновременно;
64 Кб RAM-памяти с конфигурируемым разделением и кэш-память первого уровня;
унифицированное адресное пространство с полной поддержкой языка С++;
оптимизация для работы с OpenCL и DirectCompute;
IEEE 754-2008 32-разрядная и 64-разрядная точность;
значительно улучшенная подсистема памяти: иерархия NVIDIA Parallel DataCache с конфигурируемой кэш-памятью первого уровня и унифицированной кэш-памятью второго уровня;
впервые для графических процессоров реализована поддержка кода ECC;
значительно повышенная производительность при работе с атомарными операциями;
параллельная обработка программных ядер (kernels).
|
 Главная
Главная 